DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
Abstract
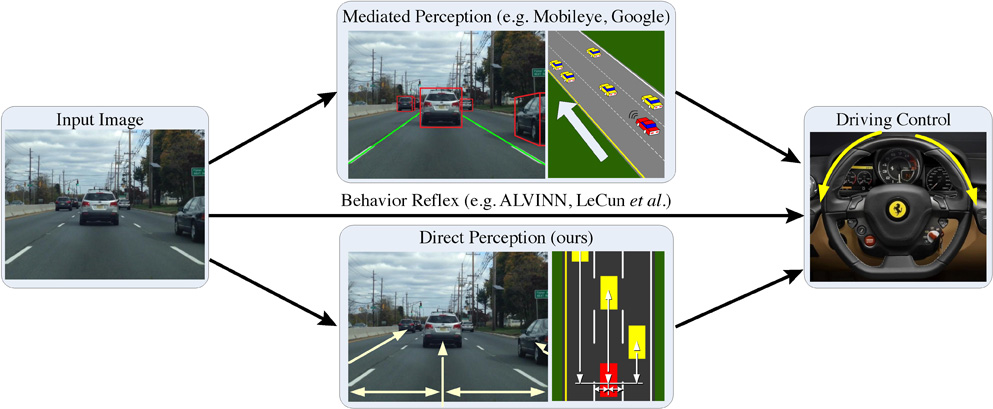
Today, there are two major paradigms for vision-based autonomous driving systems: mediated perception approaches that parse an entire scene to make a driving decision, and behavior reflex approaches that directly map an input image to a driving action by a regressor. In this paper, we propose a third paradigm: a direct perception based approach to estimate the affordance for driving. We propose to map an input image to a small number of key perception indicators that directly relate to the affordance of a road/traffic state for driving. Our representation provides a set of compact yet complete descriptions of the scene to enable a simple controller to drive autonomously. Falling in between the two extremes of mediated perception and behavior reflex, we argue that our direct perception representation provides the right level of abstraction. To demonstrate this, we train a deep Convolutional Neural Network (CNN) using 12 hours of human driving in a video game and show that our model can work well to drive a car in a very diverse set of virtual environments. Finally, we also train another CNN for car distance estimation on the KITTI dataset, results show that the direct perception approach can generalize well to real driving images.
Paper
-
C. Chen, A. Seff, A. Kornhauser and J. Xiao.
DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
Proceedings of 15th IEEE International Conference on Computer Vision (ICCV2015)
Video (Download raw video here)
See also: New video on making U-turns with DeepDriving
Source Code and Data
- DeepDrivingCode_v1.zip: Source Code and Setup File. This is the old version, please use the new one instead.
- DeepDrivingCode_v2.zip: Source Code and Setup File. Please use this version.
- TORCS_trainset.zip: The training set is in leveldb format, the images are in the integer data field, while the corresponding labels are in the float data field.
- TORCS_baseline_testset.zip: A fixed testset to compare with the baselines (Caltech lane detector and GIST).
- Note: Our real testing is to let the ConvNet to drive the car in the game. So the testing images are generated on-the-fly.
Acknowledgement
This work is partially supported by gift funds from Google, Intel and Project X grant to the Princeton Vision Group, and a hardware donation from NVIDIA.